Four months of constant coding and excitement comes to an end – I still can’t believe I am saying this. While I am really really happy with how these times went – how fast, how satisfying, how perfectly awesome it went. It is just still hard to believe that it has ended – time flies, literally!
Here goes my wrap-up blogpost for all these months of tireless programming. Here’s to a summer full of code! 🙂
Background
As I have mentioned in my last few blog posts on several updates, I have been working on the Language Coverage Matrix Dashboard project for the Language Engineering Team of Wikimedia Foundation as my Google Summer of Code project. This web-based application automates all the information that are available on the Language related topics that Wikipedia and its Sister project covers – tools they support, languages they have support for, statistics that are available for public use etc. The target users are obviously the researchers, linguists, i18 developers, and even MediaWiki developers concerned about the Language technology, willing to implement somewhere else, you know, for good!
That said, I am going to post here a detailed description of the final product that we have achieved so far.
Demo Instance: http://tools.wmflabs.org/lcm-dashboard/lcmd/
The User Interface
We have actually done a lot of thinking around the user interface throughout the period of GSoC. The final one turned out be quite satisfying. The whole page is now divided into two major parts – a) where all the queries that are available would be displayed. b) the results to show. So, now it has become same for the Language based queries, as well as the tools based ones. Filter is there for the tools based queries.
The diagram of the UI is uploaded on commons. Check it out!
Relevant Code: On GitHub!

LCMD – Landing Page
Basic Functionalities
Now that you’ve seen the UI that we have aimed to achieve. Let’s go deeper into the functionalities.
-
Search
The whole searching concept has been divided into two parts, two ways, to be specific.
- Language Based Search: Like you can see from the design and the interface that has been implemented, a search bar for the Language search is there. Essentially you get to search for all the Languages that are on the database of ours, i.e. the ones that are supported by Wikimedia Projects. jQuery.ime – a development work by the Language Engineering developers has been implemented on the search. Language search have features like : Suggestions, Auto-Completion etc, to provide users with more efficient search. Output of the search for a particular language would obviously give all the relevant details that we have for that particular language.

Language Search with autocomplete facility
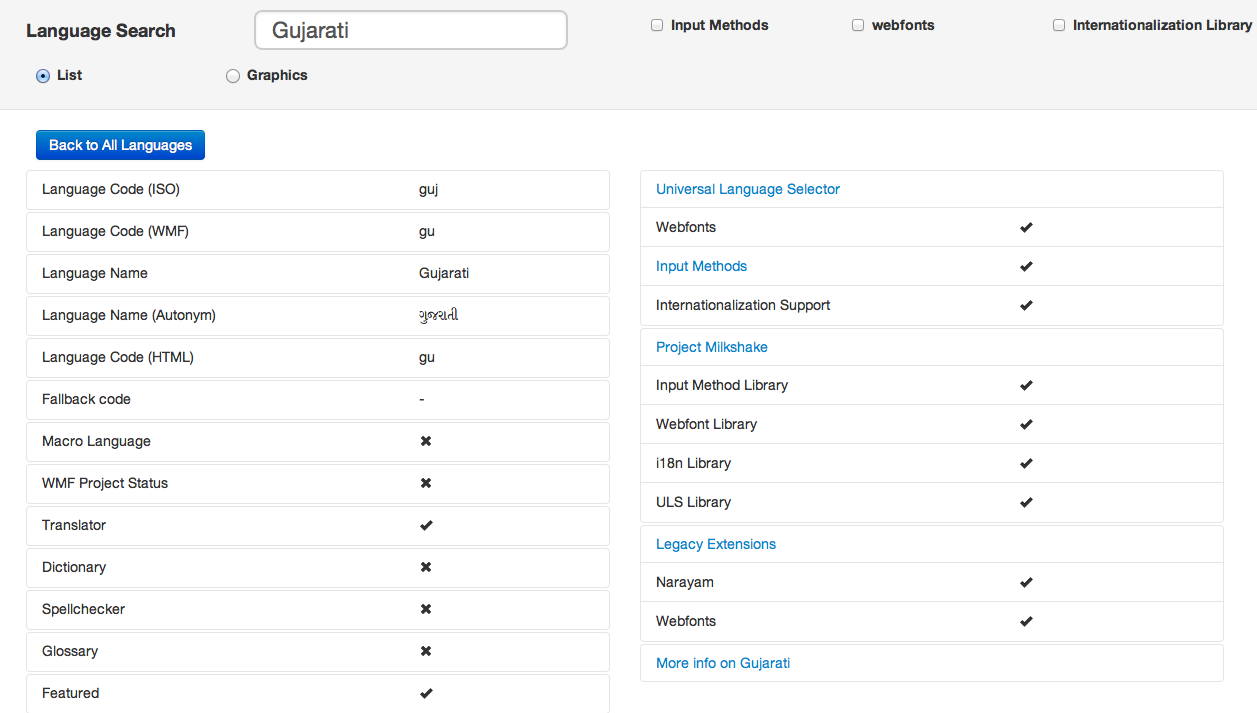
Language Search Result
- Tools Based Search: This is important. This basically a feature to play around all the language data we have. I have got a filter for that – a JS application that filters out all the language data with respect to tools based queries. So, essentially this outputs the languages that support particular tools. Tools based queries work around three basic queries –
- Input Method
- Webfonts
- Internationalization Library
-
Filter:
As mentioned above the tools based query part does have this feature where you can filter out all the language data with respect to the tools based query. A JavaScript code runs behind to have this running. Outputs the language names that support the particular tools that may be selected on the radio button
- Try it out: http://tools.wmflabs.org/lcm-dashboard/lcmd/
-
API Console
This is probably my favourite feature from LCMD. If a third party user wants to fetch these language related data then they can easily get data by calling these APIs. For better understanding of API I have developed API console.
This is similar to MediaWiki API sandbox. In which you just have to select from dropdown and then press on request button and then “BINGO”. Yes you will find- Query Formation string
- Output of Your Query
- Sample Example (How to use that Query)
- Try it out: http://tools.wmflabs.org/lcm-dashboard/lcmd/api
- Entire Information on this feature : Check it out !

Language API Console
That is almost what it is. Now a quick overview on how I have developed stuff over time, things I have just described above, and the processes behind. This would also include a few stuff that we changed afterwards. Some of the updates you might have followed on my previous blogposts, this one would work as a summary of those.
June – Community Bonding Period:
- In the community bonding period I first thought/planned about new technologies which I would be using in my project.
- Started with the database – created the database schema.
- All the data was in a spreadsheet – created one python script so that it could transfer all the data from spreadsheet to database automatically.
- The week after, I started working on new language entry system, database connection and completed it.
- Implemented language search system with suggestion for the language names.
- Implemented the feature to get the language details.
July – Coding out the Functionalities, start!
- Created and set up primary thing on Wikimedia Labs.
- Done minor changes in Language Search System.
- Created on the spot editing facility for any language detail under admin privileges
- Created Filter Facility
- Database schema changed
- jquery based new alternative REST architecture created
- Language to Font mapping
- Language to Input method mapping
- Redefining search implementation
August – Coding, coding, coding!
- Created login system for admin + session management
- Designed new UI on langfilter.php page
- Developed PI visualization chart
- Developed API for language detail
- Developed example for API usage
- Created preview system for new language entry system as well as direct editing feature
September – the last touch.
- Developed API console for 3rd party user to use these data for their website.
- Redesigned entire NEW UI as per proposed scheme
- Small correction in functionality
- Solved a few bugs
Documentations:
All the things that I have documented so far in these four months, here goes!
- Installation and Setup Guide
- Being Google Summer of Code Intern
- Wikimedia Tool setup for LCM-Dashboard (GSoC Project)
- Re – Designing LCMD – Introducing the New User Interface
- New User Experience Documentation
- Language API Console
A note to thank you all, who were there
I loved living this four months of my life. But, Google Summer of Code is not why I love Wikimedia Foundation. Rather, it is just another event that happened between the Foundation and myself. I have been an active volunteer to Wikimedia projects for a long time now. And, yes, I have been thankful for each and every day I have spent with MediaWiki, Wikipedia and the people around all those projects. GSoC has been a different kind of excitement – recognition feels good. Honestly, it does. But what feels even better than that is to get a merged status on some hundred lines of code that I have written. GSoC has given me many merges – I am thankful for each of them. Runa and Alolita have been amazing mentors to me. For all the things I have done good, for all the pushes I needed to do them that way – they have been there always. Special thanks to Quim, Sumana and Sucheta to help me throughout. I am sure, I am motivated enough to live for another four decades just to code. JUST for the sake of coding. Yes. GSoC definitely played a great part on achieving that motivation.


